Regression
Hedonic Pricing Theory
Very briefly, the theory underlying this regression analysis is the hedonic pricing theory which was pioneered by Rosen (1974). It basically states that the price of a product (AirBnB listing) can be determined by certain characteristics of the product (number of bedrooms, location etc.). In other words, the accommodation’s attributes and characteristics influence the value of the product. Accordingly, the hosts can set the prices subject to the listing’s characteristics. Hedonic pricing theory applies multiple regression analysis to find out the correlation between price and characteristics. There are, however, not many studies who identify price determinants of sharing economy based accommodations. In the same vein, on of the limitations of the hedonic pricing method lies in its limited ability to set rules for selecting variables for the analysis. As Andersson (2000, 294) puts it: “There are no theoretical arguments in favor of a specific set of independent variables”. Nevertheless, there are many studies on hotel prices which can be used as a point of reference. Typical price determinants in these hotel focused studies are location, property characteristics, quality signaling factors, hotel amenities and services and external factors like the number of close competitors.1
Airbnb pricing
Airbnb has many unique listing characteristics, for instance, the possibility of instant booking or difference in the flexibility of cancellations. In addition to that, there are many factors which can possibly influence the pricing decision of the host. Those and the different characteristics of the hosts themselves cannot be covered by the regression analysis as in most cases they are non-measurable attributes.
The variables that were measurable are divided into four different sets: distance to the closest metro station, property characteristics, rental rules, and reputational (host) characteristics. Please note, due to its great amount of missing values the host’s response rate was excluded from the model, even though it might have a significant effect on the price. Additionally, we droped the number of beds and number of bedrooms in the model as it is expected to highly correlate with the number it can accommodate.
The geography was taken into account via the two distance variables calculated in the last page, i.e. distance to the next metro station and distance to the city center (both measured in meters) To use the distance to the city center is a common proxy for the location of a listing. Nevertheless, it is clear that business travellers will choose a different location than leisure travellers who want to stay close to the main attractions.
We use the price of the listings as our dependent variable in log form. The use of the log form means that we will interpret the effects of the independent variable to percentage changes in the listing prices. In addition, as Sirmans, Macpherson, and Zietz (2005, 4) have pointed out the fact that hedonic models in logarithmic forms are very beneficial: “[…] the hedonic pricing model is often estimated in semi-log form with the natural log of price used as the dependent variable. Then the coefficient estimates allow one to calculate the percentage change in price for a one-unit change in the given variable.”
Our set of explanatory variables which will enter into an ordinary least squares (OLS) regression model with the the price (log) as the dependent variable are displayed in the following table:
| Distance | Property | Rules | Reputation |
|---|---|---|---|
| Distance to the next metro station | Apartment (Dummy) | Strict Cancellation | Review Index |
| Distance to the city center | Accomodates | Instant Booking | Superhost |
| Number of Bathrooms | Minimum nights | Listings duration |
Based on hedonic pricing theory the hypothesis can be formulated as follows:
Hypothesis 1: The smaller the distance to the closest metro station, the higher the listing price.
Hypothesis 2: Instant Bookability and flexible cancellation rules are associated with higher listing prices.
Hypothesis 3: Higher average rating scores (index) are associated with higher listing prices.
Hypothesis 4: Superhost status is associated with higher prices
Thus, our final regression equation looks like the following: \[log(price_i) = \alpha + \delta D_i + \beta R_i + \gamma U_i + \tau P_i + \epsilon_i \] where \(price_i\) reflects the individual price per night, \(\alpha\) the intercept, the vector \(D\) reflects the distance measures, the \(R\) vector contains rental listing features and the vector \(U\) is composed of rental rules and lastly \(P\) describe reputational characteristics of the listing.
Regression diagnostic
Recall that basic linear regression requires some assumptions in order to be valid: linearity (& no influential outliers), homoscedasticity of variance, independence of the error term, little or no multicollinearity and normally distributed residuals.
We checked for multicollinearity among the independent variables with the aid of the variance inflation factor (VIF) to avoid any undesired effects on the regression results and thus on our interpretation. While the VIF among the variables in any of the five models was below the threshold, a Breusch–Pagan test was assessed in order to detect heteroskedasticity. Unfortunately, in all five models we found heteroskedasticity. For this reason, we calculated robust standard errors using the vcovHC() function from the sandwich package. For more details on heteroskedasticity consistent estimators see Zeileis (2004).
Regression
The usage of the log on our dependent variable is justified when we look at the following graphs. When the data is not normally distributed a non-linear transformation (e.g., log-transformation) might fix this issue. In other words, a log transformation will make skewed distribution more normally distributed. One can clearly see that the regression in the standard, no log form, is indeed not normally distributed. Thus, it is reasonable to adjust accordingly and use the log-form henceforth.
mod_no_log <- lm(price_dkk ~ distance + dist_centrum, data = airbnb_clean)
plot_model(mod_no_log, type = "diag") %>% plot_grid()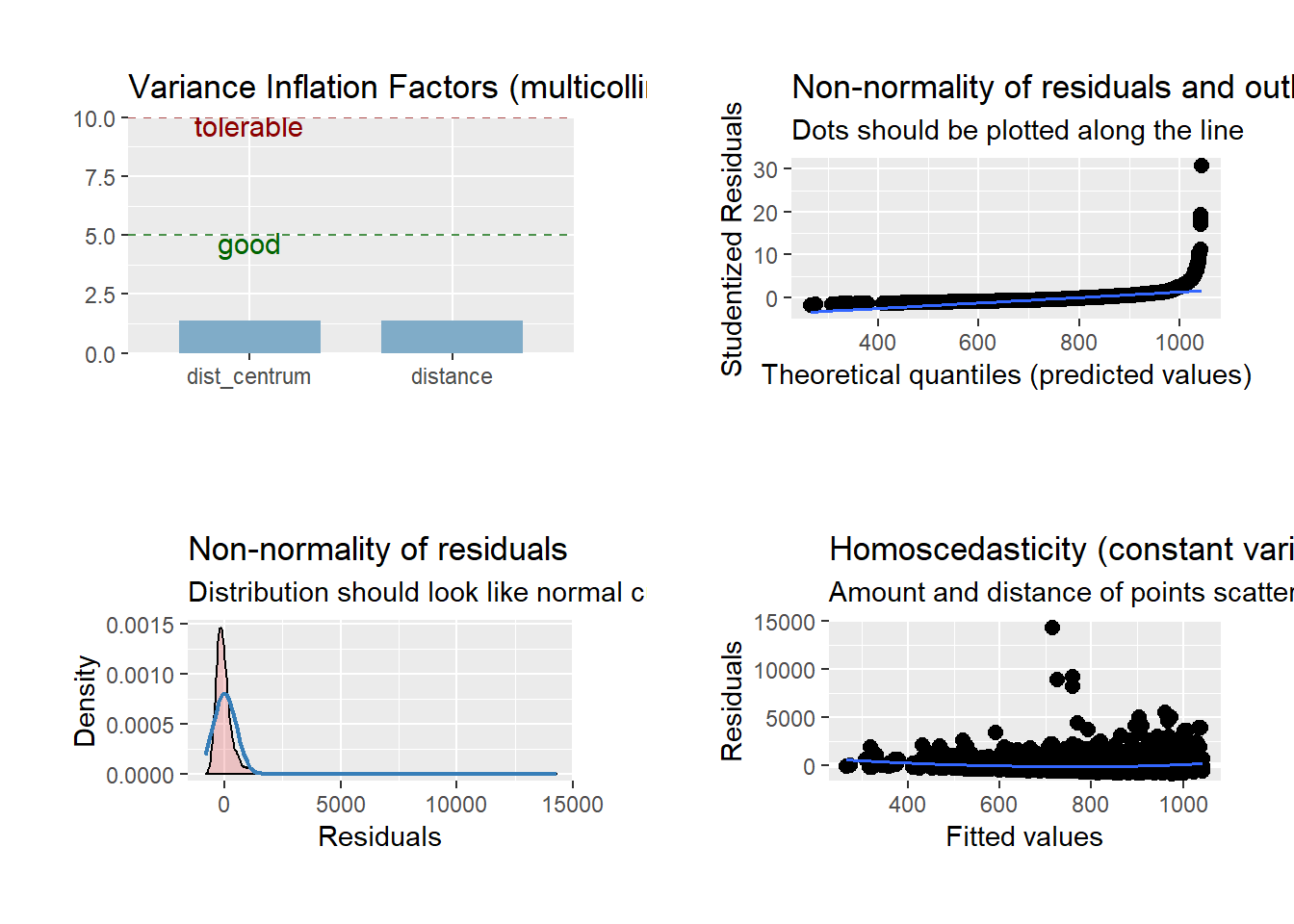
# Thus we take the log
mod1 <- lm(log(price_dkk) ~ distance + dist_centrum, data = airbnb_clean)
plot_model(mod1, type = "diag") %>% plot_grid()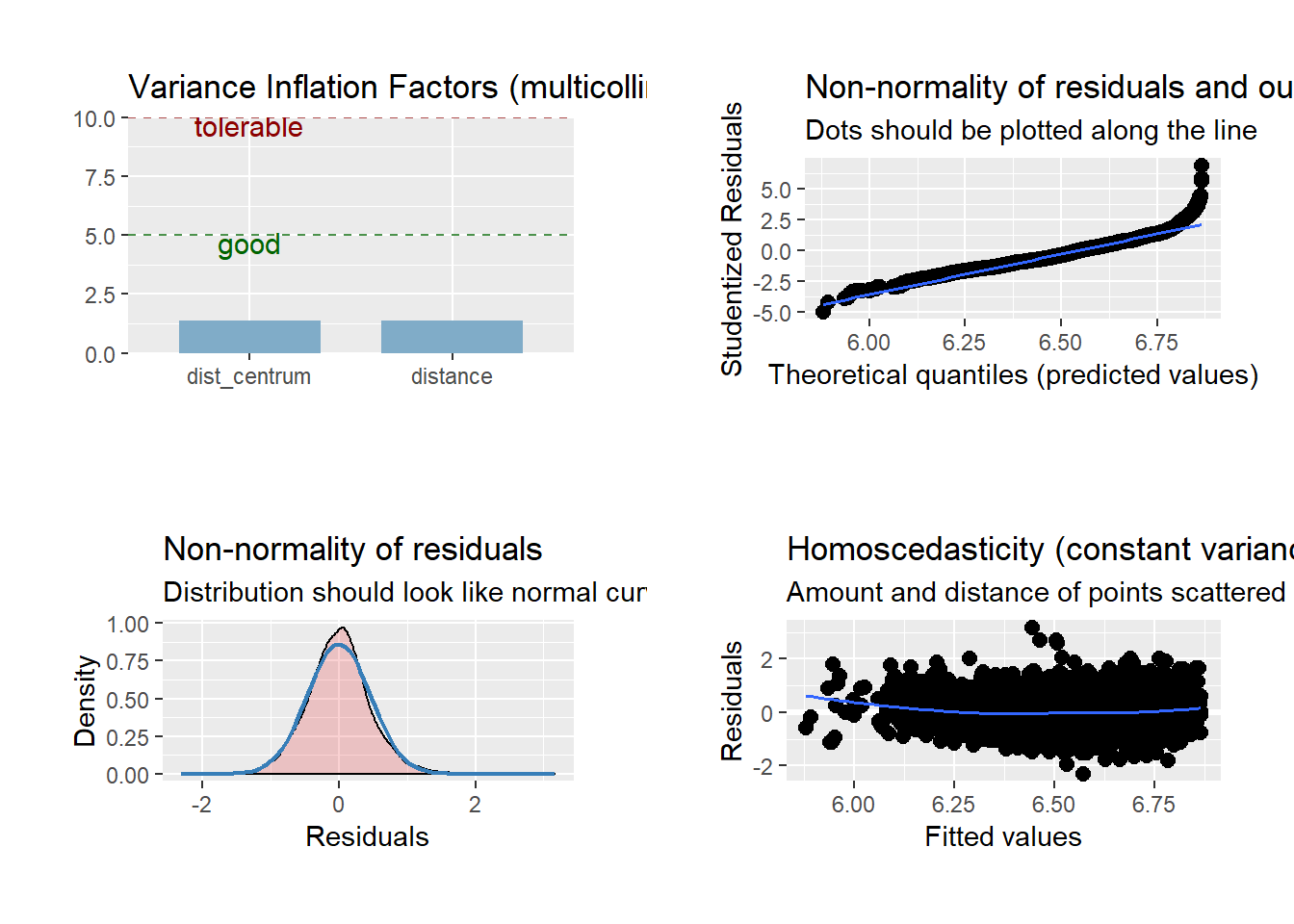
Now we can finally take a look at our whole regression model. We included the variables step by step in order to see how the coefficients change. We start first with the estimates of the distance variables on the price. We keep these variables and regress them together with each other variable set separately (Property, Rules, Reputation). Finally, we will calculate the coefficients of regression of all explanatory variable against the dependent variable.
| Log Price per night in DKK | |||||
| Distance | Property | Rules | Reputation | Full model | |
| 1 | 2 | 3 | 4 | 5 | |
| Distance Metro | -0.000*** | -0.000 | -0.000** | -0.000** | -0.000 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| Distance Centre (Proxy) | -0.000*** | -0.000*** | -0.000*** | -0.000*** | -0.000*** |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| Apartment (Dummy) | .446*** | .415*** | |||
| (.017) | (.017) | ||||
| Accomodates | .125*** | .110*** | |||
| (.004) | (.004) | ||||
| Number of Bathrooms | .259*** | .214*** | |||
| (.022) | (.022) | ||||
| Strict Cancel | .024 | .011 | |||
| (.014) | (.011) | ||||
| Instant Booking | -.022 | .011 | |||
| (.016) | (.013) | ||||
| Minimum nights | -0.000 | -0.000 | |||
| (0.000) | (0.000) | ||||
| Cleaning Fee | .001*** | 0.000*** | |||
| (0.000) | (0.000) | ||||
| Review Index | .106*** | .098*** | |||
| (.024) | (.017) | ||||
| Superhost | -.056** | .030* | |||
| (.019) | (.014) | ||||
| Listings duration | 0.000*** | 0.000*** | |||
| (0.000) | (0.000) | ||||
| Constant | 6.881*** | 5.846*** | 6.583*** | 5.827*** | 4.832*** |
| (.013) | (.028) | (.021) | (.240) | (.171) | |
| Observations | 7,534 | 3,869 | 3,869 | 3,869 | 3,869 |
| R2 | .094 | .538 | .283 | .111 | .566 |
| Adjusted R2 | .093 | .538 | .282 | .109 | .564 |
| Residual Std. Error | .463 (df = 7531) | .338 (df = 3863) | .422 (df = 3862) | .470 (df = 3863) | .329 (df = 3856) |
| F Statistic | 389.268*** (df = 2; 7531) | 901.331*** (df = 5; 3863) | 254.592*** (df = 6; 3862) | 96.024*** (df = 5; 3863) | 418.535*** (df = 12; 3856) |
| Notes: | *P < .05 | ||||
| **P < .01 | |||||
| ***P < .001 | |||||
| Log Price per night in DKK | |||||
| Distance | Property | Rules | Reputation | Full model | |
| 1 | 2 | 3 | 4 | 5 | |
| Distance Metro | -0.000** | -0.000 | -0.000** | -0.000** | -0.000 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| Distance Centre (Proxy) | -0.000*** | -0.000*** | -0.000*** | -0.000*** | -0.000*** |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| Apartment (Dummy) | .446*** | .415*** | |||
| (.016) | (.017) | ||||
| Accomodates | .125*** | .110*** | |||
| (.004) | (.005) | ||||
| Number of Bathrooms | .259*** | .214*** | |||
| (.030) | (.029) | ||||
| Strict Cancel | .024 | .011 | |||
| (.015) | (.011) | ||||
| Instant Booking | -.022 | .011 | |||
| (.018) | (.013) | ||||
| Minimum nights | -0.000 | -0.000 | |||
| (0.000) | (.001) | ||||
| Cleaning Fee | .001*** | 0.000*** | |||
| (0.000) | (0.000) | ||||
| Review Index | .106*** | .098*** | |||
| (.026) | (.019) | ||||
| Superhost | -.056** | .030* | |||
| (.019) | (.013) | ||||
| Listings duration | 0.000*** | 0.000*** | |||
| (0.000) | (0.000) | ||||
| Constant | 6.934*** | 5.846*** | 6.583*** | 5.827*** | 4.832*** |
| (.021) | (.032) | (.043) | (.256) | (.192) | |
| Notes: | *P < .05 | ||||
| **P < .01 | |||||
| ***P < .001 | |||||
Discussion
The distance to the city center does have a significant, but very small effect on the price of the listing which is negative. The further away the listing is located, the less is its price. If we change \(x\) by \(1\) (unit), we’d expect our y variable to change by \(100⋅\beta_1\) percent. In this case it means if the house is located 1 meter further away from Nyhavn, the city center, it decreases its price by 0.001%. If the listing is, for instance, 1km further away, ceteris paribus approximately on average it reduces its price by 1%.
The distance to the closest metro does not have a significant effect.
Property characteristics that are positively associated with the listings price are the type (Apartment), how many people it can accommodate and the number of bathrooms. All are highly signifacnt at the 0.1 percent level.
The listings specific rental rules like instant bookable rentals or strict cancellation policies do not have the expected effect.
Lastly, higher values on our review index (meaning an better overall rating), the superhost badge and the duration the listings is available are associated with a markp-up on the price.
Limitations
There are some limitations concerning the data used in the analysis. Although the provision of data from AirbnbInside.com is very useful, it is clear that there will be a difference between advertised listings and booked listings. The problem is that some of the advertised listings, which is the basis for the InsideAirbnb-dataset, are outdated or created by accident and are thus not booked. I tried to control for this by setting a minimum requirement concerning the number of reviews as well as the verification of the host as a necessary condition. “Scrapers that track updates to host calendars cannot distinguish real bookings from dates host block for other reasons.” (Coles et al. 2017)
Coles et al. (2017) also point to the fact that there is a discrepancy between the price listed and the actual transaction price. The scraping method does not include any corrections for specific discounts, i.e. weekly discount.
In addition to that, in a next analysis, a researcher could investigate the influence factor of a specific neighborhood on the price of the listing. It can be expected that the more known/appealing a neighborhood is, the more it will cost for both the host (rent) and the guest (listing price).
Final Findings Summarized:
Distance to the closest metro station does not affect the price of the rental. We can interpret this result from the lens of a visitor who is looking for a potential accommodation. The result suggest that, from a utility maximazing point of view, a visitor should always include a short distance to the next metro station into his personal search. It will not be to his or her disadvantage.
Higher prices are associated with the number of bathrooms, how many people the listing can accommodate and the reputation of the listings displayed in its reviews.
Cancellation policies are fairly spread out, but the analysis showed that the expected relationship cannot be detected in the data. It seems to have no effect on the price of the listing.
However, there is no (significant) relationship between the rental price and the number of minimum nights or the possibility to book a listing instantly.
Recommendation
Which effect does the distance to the closest metro station have on the price of the accommodation? The analysis showed that it the distance is not included in the price, yet. In my opinion it is a good thing that it is not reflected in the price. If we overlook the possibility of misspecification of the model, it hints at the fact that accoding to the hedonic price model hosts do not account for this characteristic in their pricing strategy - even though it provides additional value to the consumer. I would, therefore, encourage future visitors to check (Google-) the location of the AirBnB before booking. If it rains you will thank me for it.
References
Andersson, David E. 2000. “Hypothesis Testing in Hedonic Price Estimation–On the Selection of Independent Variables.” The Annals of Regional Science 34 (2). Springer: 293–304.
Coles, Peter A, Michael Egesdal, Ingrid Gould Ellen, Xiaodi Li, and Arun Sundararajan. 2017. “Airbnb Usage Across New York City Neighborhoods: Geographic Patterns and Regulatory Implications.” Forthcoming, Cambridge Handbook on the Law of the Sharing Economy.
Rosen, Sherwin. 1974. “Hedonic Prices and Implicit Markets: Product Differentiation in Pure Competition.” Journal of Political Economy 82 (1). The University of Chicago Press: 34–55.
Sirmans, Stacy, David Macpherson, and Emily Zietz. 2005. “The Composition of Hedonic Pricing Models.” Journal of Real Estate Literature 13 (1). American Real Estate Society: 1–44.
Wang, Dan, and Juan L Nicolau. 2017. “Price Determinants of Sharing Economy Based Accommodation Rental: A Study of Listings from 33 Cities on Airbnb. Com.” International Journal of Hospitality Management 62. Elsevier: 120–31.
Zeileis, Achim. 2004. “Econometric Computing with Hc and Hac Covariance Matrix Estimators.” Institut für Statistik und Mathematik, WU Vienna University of Economics and ….
See Wang and Nicolau (2017) for a comprehensive list of studies on hotel price determinants.↩